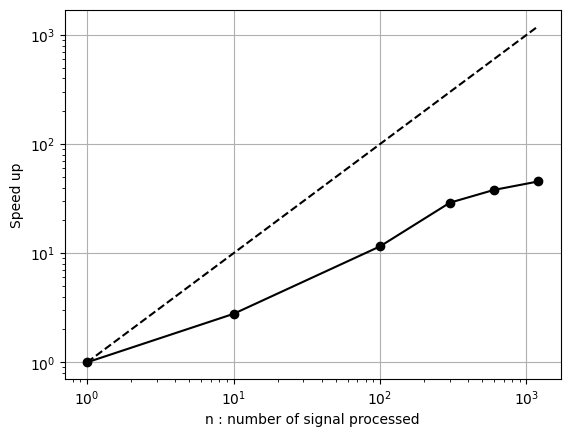
Matched-Field Processing - Speed up¶
The match-field processing performed in this code is inspired from the one describe in this git repository. The description below is taken from this repository.
The beamformer formulation is written in the frequency domain as:
where \(K_{jk}(\omega) = d_j(\omega) d_k^H(\omega)\) is the cross-spectral density matrix of the recorded signals \(d\), and \(S_{jk}(\omega) = s_j(\omega) s_k^H(\omega)\) is the cross-spectral density matrix of the synthetic signals \(s\).
Here, \(j\) and \(k\) identify sensors, and \(H\) denotes the complex conjugate. Auto-correlations (\(j = k\)) are excluded because they contain no phase information. Consequently, negative beam powers indicate anti-correlation.
The synthetic signals \(s\) (often called replica vectors or Green’s functions) represent the expected wavefield for a given source origin and medium velocity, most often in an acoustic homogeneous half-space \(s_j = \exp(-i \omega t_j)\) where \(t_j\) is the travel time from the source to each receiver \(j\).
The travel time is computed as:
with \(| \mathbf{r}_j - \mathbf{r}_s |\) being the Euclidean distance between the sensor and the source, and \(c\) the medium velocity.
Using this formulation the Bartlett \(B\) in contained in \([-1,1]\).
[1]:
# specific das_ice function
import das_ice.io as di_io
import das_ice.signal.filter as di_filter
import das_ice.processes as di_p
import das_ice.plot as di_plt
import das_ice.mfp as di_mpf
# classic librairy
import time
import xarray as xr
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
from tqdm import trange
%matplotlib inline
[2]:
from dask.distributed import Client,LocalCluster
cluster = LocalCluster(n_workers=8)
client = Client(cluster)
client.dashboard_link
/home/chauvet/miniforge3/envs/das_ice/lib/python3.11/site-packages/distributed/node.py:182: UserWarning: Port 8787 is already in use.
Perhaps you already have a cluster running?
Hosting the HTTP server on port 44353 instead
warnings.warn(
[2]:
'http://127.0.0.1:44353/status'
Data pre-processing¶
[3]:
ds=xr.Dataset()
ds['velocity']=di_io.dask_Terra15('*.hdf5', chunks="auto")
[4]:
d_optic_bottom=2505 #m
depth_bh=97 #m
[5]:
ds=ds.sel(distance=slice(d_optic_bottom-depth_bh,d_optic_bottom+depth_bh))
[6]:
ds['distance']=-1*(np.abs(ds.distance-d_optic_bottom)-depth_bh)
ds = ds.sortby('distance')
[7]:
dsr=di_p.strain_rate(ds.velocity).T
Compute grid search¶
To compute the grid search you need to provide the postion of each sensor along the optic fiber. Here, the optic distance is used in order to provid the position relative to the surface of the glacier.
[8]:
stations=np.array([np.zeros(len(dsr.distance)),dsr.distance.values]).T
In this example, the beamformer is compute for every sub-sample of \(0.1~s\) without overlap over a spatial and temporal grid :
along \(x\) : from \(0~m\) to \(120~m\) with a step of \(2~m\)
along \(z\) : from \(0~m\) to \(100~m\) with a step of \(2~m\)
along \(c\) : from \(3400~m.s^{-1}\) to \(3600~m.s^{-1}\) with a step of \(100~m.s^{-1}\)
[9]:
freqrange=[100,200]
ti='2024-08-29T05:05:00'
tf='2024-08-29T05:07:00'
[10]:
MFP=di_mpf.MFP_2D_series(dsr.sel(time=slice(ti,tf)),0.1,stations,xrange=[0,120],zrange=[0,100],vrange=[3400,3600],dx=2,dz=2,dv=100,freqrange=freqrange)
/home/chauvet/miniforge3/envs/das_ice/lib/python3.11/site-packages/distributed/client.py:3362: UserWarning: Sending large graph of size 474.79 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2024-12-04 15:49:48,323 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 3.19 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:49:52,470 - distributed.worker.memory - WARNING - Worker is at 86% memory usage. Pausing worker. Process memory: 3.33 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:49:57,509 - distributed.worker.memory - WARNING - Worker is at 81% memory usage. Pausing worker. Process memory: 3.14 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:49:57,596 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 3.16 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:49:59,866 - distributed.worker.memory - WARNING - Worker is at 7% memory usage. Resuming worker. Process memory: 292.79 MiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:00,322 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 3.00 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:00,389 - distributed.worker.memory - WARNING - Worker is at 81% memory usage. Pausing worker. Process memory: 3.14 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:00,636 - distributed.worker.memory - WARNING - Worker is at 6% memory usage. Resuming worker. Process memory: 268.22 MiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:01,801 - distributed.worker.memory - WARNING - Worker is at 86% memory usage. Pausing worker. Process memory: 3.36 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:03,388 - distributed.worker.memory - WARNING - Worker is at 7% memory usage. Resuming worker. Process memory: 315.20 MiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:03,871 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.76 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:04,256 - distributed.worker.memory - WARNING - Worker is at 81% memory usage. Pausing worker. Process memory: 3.16 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:05,560 - distributed.worker.memory - WARNING - Worker is at 87% memory usage. Pausing worker. Process memory: 3.38 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:06,111 - distributed.worker.memory - WARNING - Worker is at 86% memory usage. Pausing worker. Process memory: 3.33 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:07,501 - distributed.worker.memory - WARNING - Worker is at 4% memory usage. Resuming worker. Process memory: 195.65 MiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:07,960 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.87 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:08,110 - distributed.worker.memory - WARNING - Worker is at 84% memory usage. Pausing worker. Process memory: 3.26 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:08,319 - distributed.worker.memory - WARNING - Worker is at 6% memory usage. Resuming worker. Process memory: 267.83 MiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:09,486 - distributed.worker.memory - WARNING - Worker is at 84% memory usage. Pausing worker. Process memory: 3.26 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:10,394 - distributed.worker.memory - WARNING - Worker is at 7% memory usage. Resuming worker. Process memory: 311.75 MiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:50:12,171 - distributed.worker.memory - WARNING - Worker is at 87% memory usage. Pausing worker. Process memory: 3.38 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:51:26,220 - distributed.worker.memory - WARNING - Worker is at 5% memory usage. Resuming worker. Process memory: 206.14 MiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:54:57,674 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 3.41 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:55:00,350 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 3.43 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:55:07,964 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 3.43 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:56:31,691 - distributed.worker.memory - WARNING - Worker is at 8% memory usage. Resuming worker. Process memory: 346.84 MiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:56:36,734 - distributed.worker.memory - WARNING - Worker is at 9% memory usage. Resuming worker. Process memory: 369.12 MiB -- Worker memory limit: 3.87 GiB
2024-12-04 15:56:41,345 - distributed.worker.memory - WARNING - Worker is at 9% memory usage. Resuming worker. Process memory: 365.27 MiB -- Worker memory limit: 3.87 GiB
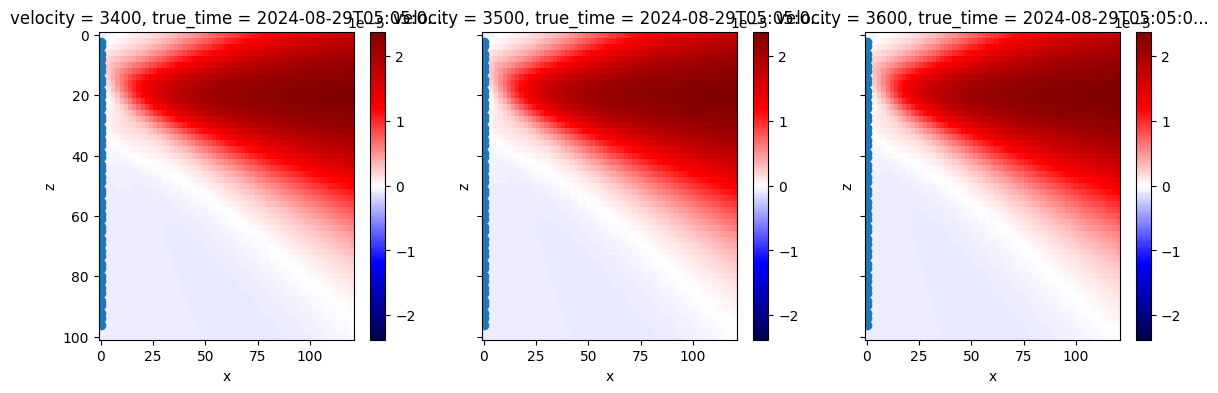
Extract Bartlett value¶
In this section, it is shown how to extract the maximum Bartlett value for each sample of \(0.1~s\).
[11]:
bc_max=MFP.max(dim=['z','x','velocity'])
pos_bc_max=[]
for i in range(len(MFP.true_time)):
sources_find=MFP[...,i].where(MFP[...,i] == bc_max[i], drop=True).coords
pos_bc_max.append([sources_find['x'].values[0],sources_find['z'].values[0],sources_find['velocity'].values[0],bc_max[i]])
bc=xr.DataArray(np.stack(pos_bc_max),dims=['true_time','bc'])
bc['true_time']=MFP.true_time
[12]:
i=0
fig, axs = plt.subplots(1, 3, sharey=True, sharex=True, figsize=(14, 4))
MFP[...,0,i].plot(yincrease=False,ax=axs[0],vmin=-bc[i,3],vmax=bc[i,3],cmap='seismic')
MFP[...,1,i].plot(yincrease=False,ax=axs[1],vmin=-bc[i,3],vmax=bc[i,3],cmap='seismic')
MFP[...,2,i].plot(yincrease=False,ax=axs[2],vmin=-bc[i,3],vmax=bc[i,3],cmap='seismic')
axs[0].scatter(stations[:,0],stations[:,1],label='stations')
axs[1].scatter(stations[:,0],stations[:,1],label='stations')
axs[2].scatter(stations[:,0],stations[:,1],label='stations')
#if MFP['v'][i]==sources_find['v']:
# plt.scatter(sources_find['x'][0],sources_find['z'],marker='^',label='best beam')
[12]:
<matplotlib.collections.PathCollection at 0x7d8210413250>
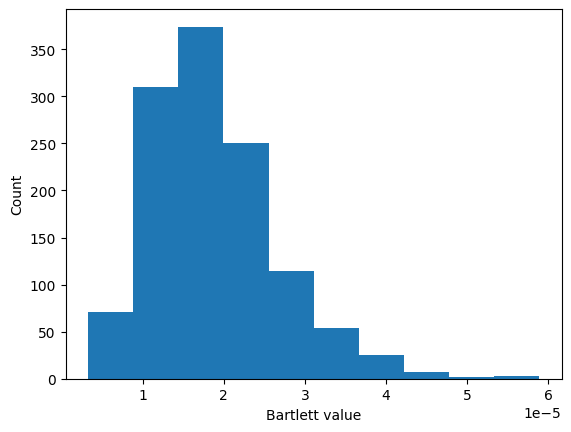
[13]:
plt.hist(bc.values[:,3])
plt.ylabel('Count')
plt.xlabel('Bartlett value')
[13]:
Text(0.5, 0, 'Bartlett value')
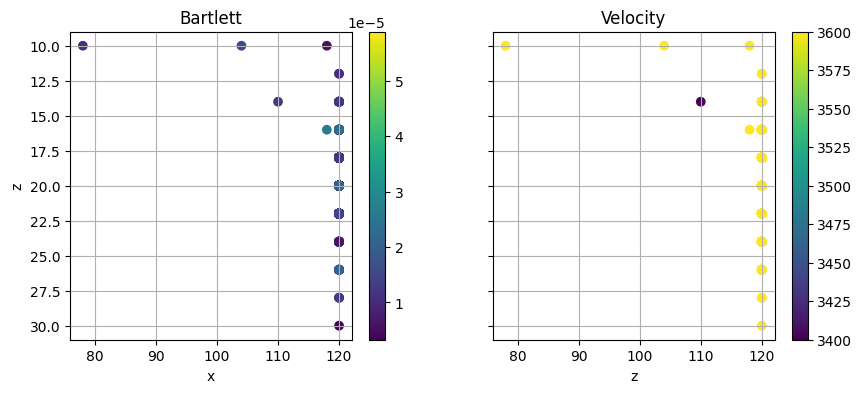
[14]:
fig, axs = plt.subplots(1, 2, sharey=True, sharex=True, figsize=(10, 4))
scatter1=axs[0].scatter(bc.values[:,0],bc.values[:,1],c=bc.values[:,3])
fig.colorbar(scatter1, ax=axs[0])
axs[0].invert_yaxis()
axs[0].grid()
scatter2=axs[1].scatter(bc.values[:,0],bc.values[:,1],c=bc.values[:,2])
fig.colorbar(scatter2, ax=axs[1])
#axs[1].invert_yaxis()
axs[1].grid()
axs[0].set_xlabel('x')
axs[1].set_xlabel('x')
axs[0].set_ylabel('z')
axs[1].set_xlabel('z')
axs[0].set_title('Bartlett')
axs[1].set_title('Velocity')
[14]:
Text(0.5, 1.0, 'Velocity')
Code efficiency¶
In this exemple we performed multiple MFP in order to look at the numerical efficiency of the algorimth.
[15]:
ti='2024-08-29T05:05:00'
tf=['2024-08-29T05:05:00.1','2024-08-29T05:05:01','2024-08-29T05:05:10','2024-08-29T05:05:30','2024-08-29T05:06:00','2024-08-29T05:07:00']
run_time=[]
for ttf in tf:
stime=time.time()
MFP=di_mpf.MFP_2D_series(dsr.sel(time=slice(ti,ttf)),0.1,stations,xrange=[0,100],zrange=[0,100],vrange=[2500,3500],dx=2,dz=2,dv=500)
etime=time.time()
run_time.append(etime-stime)
/home/chauvet/Documents/Projets/Gricad/das_ice/das_ice/mfp.py:28: UserWarning: The given NumPy array is not writable, and PyTorch does not support non-writable tensors. This means writing to this tensor will result in undefined behavior. You may want to copy the array to protect its data or make it writable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ../torch/csrc/utils/tensor_numpy.cpp:206.)
multi_waveform_spectra=torch.fft.fft(torch.from_numpy(ds_cube.values),axis=2).to(dtype=torch.complex128)
/home/chauvet/miniforge3/envs/das_ice/lib/python3.11/site-packages/distributed/client.py:3362: UserWarning: Sending large graph of size 56.30 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/home/chauvet/miniforge3/envs/das_ice/lib/python3.11/site-packages/distributed/client.py:3362: UserWarning: Sending large graph of size 62.70 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
/home/chauvet/miniforge3/envs/das_ice/lib/python3.11/site-packages/distributed/client.py:3362: UserWarning: Sending large graph of size 93.04 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2024-12-04 15:57:30,288 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.77 GiB -- Worker memory limit: 3.87 GiB
/home/chauvet/miniforge3/envs/das_ice/lib/python3.11/site-packages/distributed/client.py:3362: UserWarning: Sending large graph of size 160.45 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2024-12-04 15:59:13,337 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.83 GiB -- Worker memory limit: 3.87 GiB
/home/chauvet/miniforge3/envs/das_ice/lib/python3.11/site-packages/distributed/client.py:3362: UserWarning: Sending large graph of size 261.57 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2024-12-04 16:03:32,484 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.80 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 16:03:39,506 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.85 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 16:08:32,563 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.97 GiB -- Worker memory limit: 3.87 GiB
/home/chauvet/miniforge3/envs/das_ice/lib/python3.11/site-packages/distributed/client.py:3362: UserWarning: Sending large graph of size 463.81 MiB.
This may cause some slowdown.
Consider loading the data with Dask directly
or using futures or delayed objects to embed the data into the graph without repetition.
See also https://docs.dask.org/en/stable/best-practices.html#load-data-with-dask for more information.
warnings.warn(
2024-12-04 16:09:19,938 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.93 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 16:09:28,883 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.82 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 16:09:31,961 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.90 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 16:14:19,970 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 3.03 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 16:14:28,972 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.89 GiB -- Worker memory limit: 3.87 GiB
2024-12-04 16:14:32,049 - distributed.worker.memory - WARNING - Unmanaged memory use is high. This may indicate a memory leak or the memory may not be released to the OS; see https://distributed.dask.org/en/latest/worker-memory.html#memory-not-released-back-to-the-os for more information. -- Unmanaged memory: 2.90 GiB -- Worker memory limit: 3.87 GiB
The reference time \(t_{0.1}\) is the time to process one signal of \(0.1~s\). Therefore, the speed up is compute as the duration time to process \(n\) signals of \(0.1~s\) over \(t_{0.1}\).
[16]:
plt.loglog(np.array([0.1,1,10,30,60,120])/0.1,np.array(run_time)/run_time[0],'ko-')
plt.loglog([1,1200],[1,1200],'k--')
plt.ylabel(r'Speed up')
plt.xlabel('n : number of signal processed')
plt.grid()